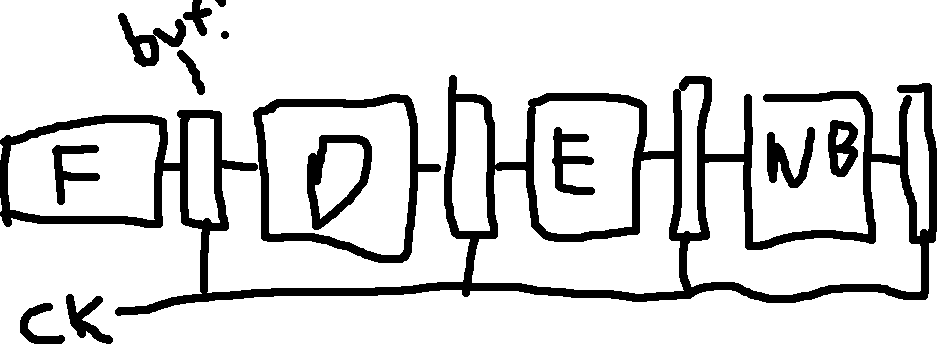
Majority of the time, we are writing data to registers.
To execute just one instruction, we have to do:
Fetch: Bring the instruction into the CPU
Decode: Find out what is this instruction
Execute: Perform the instruction
Writeback: Write data to register/
Suppose each step takes 1 nanosecond to execute
F1
D1
E1
WB1
1ns
1ns
1ns
1ns
This will take 4 ns.
Now, suppose we want to ad a second instruction
F1
D1
E1
WB1
F2
D2
E2
WB2
1ns
1ns
1ns
1ns
1ns
1ns
1ns
1ns
This will 8 ns.
so on and so forth.
Pipelining is about looking at when the machine is at D1 and seeing that the hardware that was used for F1 is now free and needlessly idling, so instead we can do this:
F1
D1
E1
WB1
F2
D2
E2
WB2
1ns
1ns
1ns
1ns
1ns
Now, every new instruction only adds 1ns rather than 4ns.
This is the execution of on instruction:
F
D
E
WB
Modular v.s. Whole System: You can swap parts out in a modular system, but not in a whole system.
A real pipeline actually has overhead.
Here, we use buffers to control the flow of input.
Doodle
This is a synchronous solution.
Alternative: Async
We won’t go over async pipelining in this class.
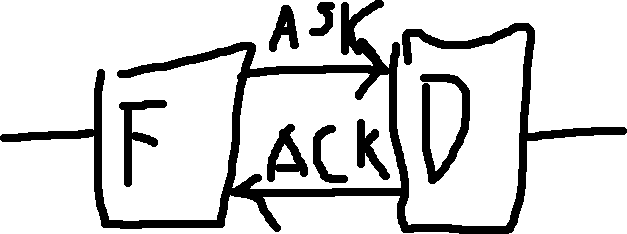
Another solution, is ask and ack architecture (asyncronous).
Ask / Request: Can I send the information?
Ack: Yes (acknowledge)
Nack: No (reject)
Doodle
Speed
To calculate speed, we need to calculate:
Delay without pipelining.
Delay with pipelining.
Doodle
# of Instructions
Delay without Pipelining
Delay with Pipelining
1
k\tau
k\tau
2
2k\tau
k + 1\tau
3
3k\tau
k + 2\tau
N
Nk\tau
k + (N-1)\tau
k: Parts
\tau: Delay
\text{Speedup} = \frac{
\text{Delay without piplining}
}{
\text{Delay with piplining}
} =
\frac{
Nk\tau
}{
k+(N-1)\tau
}
Speedup as n \to \inf:
\lim_{N \to \inf} \frac{
Nk
}{
k+(N-1)
} = k
On Architectures
The Problem
F1
D1
E1
WB1
F2
D2
E2
WB2
F3
D3
E3
WB3
Imagine the first instruction is load R1, addr1
Execution: Bring data from addr1 into the CPU.
This means that it conflicts with F3 (bringing instruction 3 into CPU), because the bus is occupied for E1.
Solutions
Bad Solution I: Introduce a delay to all instructions.
Prob: Introduces delays even when unnecessary.
Bad Solution II: Introduce a delay to just F3 (NOP).
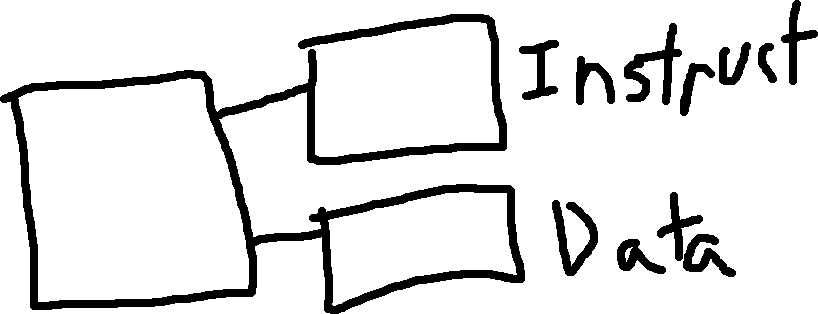
Better Solution: Harvard Architecture: Separate instruction and data memory into separate lines.
Higher complexity, and the memory cannot be reused to help the other.
harvard
Better Solution: Von Neuman Architecture: Instruction and data memory are the same.
von
Best Solution: BMW Architecture: Instruction and data memory are the same, but separate lines are provided for each.
This is the architecture all CPUs today use, without exception.
bmw
On ALU
ALU
F1
D1
E1
WB1
F2
D2
E2
WB2
Imagine the instructions are:
ADD R1, R2, R3
R1 <- R2 + R3
SUB R4, R1, R5
R4 <- R1 - R5
At E2, we see the instruction wants to use R1, but the R1 that was just modified hasn’t been written to the register on WB1 yet.
Bad Solutions:
F1
D1
E1
WB1
F2
D2
E2
WB2
F1
D1
E1
WB1
NOP
NOP
F2
D2
E2
WB2
Delay all, or delay single (NOP)
This is even worse because we’ll need 2 delays to push F2 past WB1.
Better Solutions: Instead of dealing with writing R1 just to read R1, you can short circuit R1 in the ALU to make the result immediately available before WB1.
HOTWIRE
More on Limits
So far we’ve been dealing with stable \tau
But, what if a step takes 2\tau?
F
D
E
WB
\tau
\tau
2\tau
\tau
As we can see on E, the clock frequency gets divided by two.
Why not just increase k (pipelining)?
Because remember, we need registers between every modules, which introduces a slowdown of about 10%.
Assorted Questions
Q: What is the physical limit of pipelining?
A: If the stage delay is more than 10 times of the delay of the latch.
Q: How to we fix the following:
So far we’ve been dealing with stable \tau
But, what if a step takes 2\tau?
F
D
E
WB
\tau
\tau
2\tau
\tau
Because of E, the clock frequency gets divided by two.
A: Divide the execution part by two.
F
D
E_1
E_2
WB
\tau
\tau
\tau
\tau
Q: Okay, so what if in some cases, we don’t need E_2?
e.g., ADD R1, R2, R3 might be really fast; but Load R1, Memory1 might take 2x longer.
A: “You are using a perfect pipeling, and thus everything will be the same”
Q: Why can we never have the ideal speedup?
A: Because of instruction dependency. Recall these two conflicts:
The load example uses the bus while F3 wants to run.
Doing R1 <- R2 + R3 followed by R4 <- R1 + R5 and having to account for R1 not being available.